Now that we, and by "we" I mean "I", have a full copy of the Project Gutenberg archive, the first thing I can do before publishing it is to have a look at what's actually there, keeping in mind the objective of separating the wheat from the chaff. However, before finding out what's there, there's the question of what "finding out what's there" even means: ideally, one'd catalogue everything, which is, I guess, not such a difficult task, given that the archive already contains some metadata; also, it's conceivable that one would want to verify the authenticity of (some of) the writings, which is hard, or maybe downright sisyphean if we're to consider every single text on gutenberg.org1.
For now, we're going to narrow down the scope of this "finding out what's there" to discovering what file types there are, how many of them and how much they weigh in bytes. To this end, I'm publishing a script called dissect-guten.bash, that, for each file in the gutenberg.org archive:
- looks at its extension, and
- if the extension exists, i.e. if the file is of the form
$name.$ext, then - it increments a counter
num[$ext], and - it adds the size of the file to a byte-counter
siz[$ext]
The full code:
#!/bin/bash
declare -A num
declare -A siz
print_data() {
echo "--------------"
for key in "${!num[@]}"; do
echo ${key}:${num[${key}]}:${siz[${key}]}
done
exit 1
}
# Print data if we press ctrl+c
trap print_data SIGINT
# Can't use find guten | while read line ... because this will spawn a
# sub-shell where all our updates will be lost.
while read line; do
fn=$(basename -- $line)
ext="${fn##*.}"
if [ ! ( ( "${fn}" = "${ext}" ) -o ( -z "${ext}" ) ) ]; then
fsize=$(stat -c "%s" $line)
if [ -z ${num["${ext}"]} ]; then
num+=(["${ext}"]=1)
siz+=(["${ext}"]="${fsize}")
else
num+=(["${ext}"]=$(echo ${num["${ext}"]} + 1
| BC_LINE_LENGTH=0 bc))
siz+=(["${ext}"]=$(echo ${siz["${ext}"]} + ${fsize}
| BC_LINE_LENGTH=0 bc))
fi
>&2 echo "${ext}:${num["${ext}"]}:${siz["${ext}"]}"
fi
done < <(find guten/)
print_data
The script is unfortunately a set of shitty bash-isms, but otherwise it
is fairly short and readable. Running this in a directory where guten/
is present and redirecting standard output to, say,
file-types.txt, yields a result that I won't recount
in full in the post, but that, in short, consists of a set of lines of
the form:
ext:n:siz
where ext is a file extension, n is the number of files bearing said
extension and siz is the total size in bytes. We can then e.g.:
$ sort -t: -nk3 file-types.txt > ~/file-types-sorted.txt
$ awk -F':' '{print $1,$2,$3,($3/(1024*1024*1024)),$3/$2/(1024*1024)}'
~/file-types-sorted.txt
and further massage the data set to obtain a fancy graph, such as:
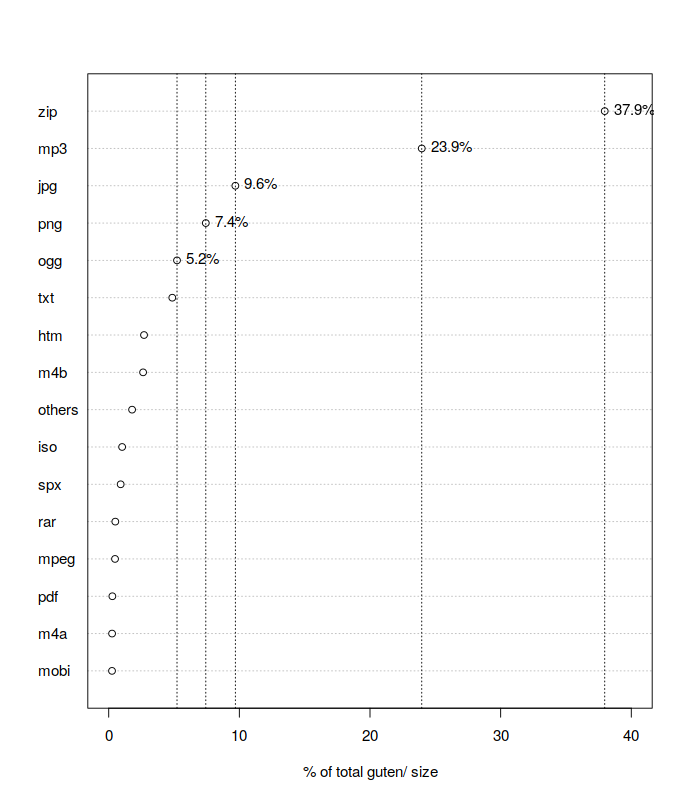
which reveals to us that the biggest offenders are zip archives2 (~300GB), mp3 and ogg files (~230GB total), images (~140GB total) and video files (a bit over 20GB), with the rest being pdf, epub, iso etc. and, finally, ~40GB representing actual text files.
Of course, the text files can be further cut by removing e.g. copyright headers3, the illustrations can be given a thorough review to establish what's actually worth keeping, but we'll leave these for the next episodes of this saga.
-
Although I'm not sure that's worth the effort, given that much of the writing might be garbage. To be honest, I have no idea. ↩
-
Looking a bit deeper at this, the zip files contain various "versions" of the book, e.g. the HTML files plus illustrations. This yields a lot of duplicate data. For example:
$ ls -1 guten/2/2/2/2/22229/22229*.zip guten/2/2/2/2/22229/22229-8.zip guten/2/2/2/2/22229/22229-h.zip guten/2/2/2/2/22229/22229.zipWhere the
-h.zipfile contains the HTML book, the-8.zipfile contains the same thing in some non-ASCII text format and finally22229.zipcontains the ASCII text file. ↩ -
Let us remember that there is only one type of "intellectual property": that in which something is owned by being thoroughly examined and understood in depth, layer by layer. Sure, this is further away from "copyright" (and other such fictions) than the average orc mind can conceive; but really, who cares? By now there is little hope left for those who aren't aware of it.
And now, assuming you've understood the previous paragraph and have come to a realization regarding the value of actual intellectual work, imagine the entirety of modern journalism and popular culture produced in the last few decades, the music and movie "industries", all the "best-sellers", the academic wank and so on and so forth. Imagine all that and how worthless a pile of junk it is -- I'm sure Gutenberg himself would have been in awe looking at all the multilaterally valuable intellectual stuff published in the late 20th/early 21st century! ↩